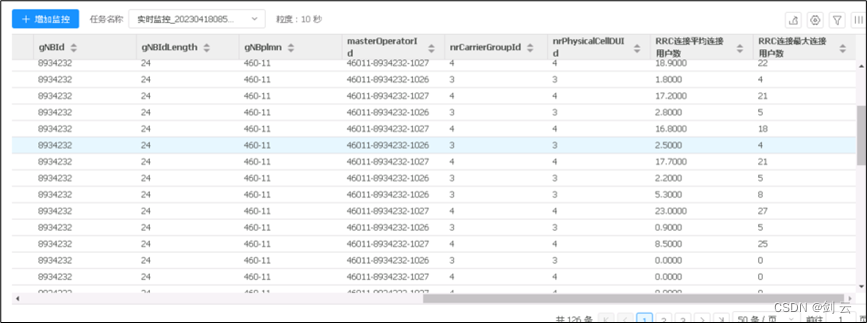
语音的产生涉及器官的复杂协调,因此,语音包含了有关身体各个方面的信息,从认知状态和心理状态到呼吸条件。近十年来,研究者致力于发现和利用语音生物标志物——即与特定疾病相关的语音特征,用于诊断。随着人工智能(AI)的进步,这些生物标志物的学习关联和临床预测变得更加可行。自动语音评估利用语音生物标志物、AI和移动技术进行远程患者健康评估,预期将为早期识别和远程监测带来许多好处。
研究人员对将深度学习应用于自动语音评估,主要有两种方法:
- 端到端训练: 模型直接从音频中做出临床预测,但需要大量手动标注数据。
- 预训练模型微调: 使用在大型语音语料库上预训练的深度学习模型作为特征提取器,并用少量标注数据进行微调。这种模型学习了一组特征,即表示,以捕获语音的属性,并可用于各种语音识别任务。
语音表示捕获了人类感知理解,并在语音中保持了一致的属性,如说话者、语言、情感和年龄。由于语音包含了有关几个重要器官状况的丰富信息,随着这些模型的兴起,已有几项工作探索并评估了它们在识别疾病方面的潜力。然而,深度学习模型缺乏可解释性,这限制了它们在医疗领域的应用。为了解决这个问题,研究人员开发了工具来理解模型的工作原理,这些工具通常分为两大类:白盒方法和黑盒方法。
- 白盒方法:这类方法通过分析数学关系来提供模型如何在特定情况下从输入推断输出的局部解释。通常需要特定的模型架构和属性,例如激活函数的存在。在神经网络中,有基于梯度的方法,如Grad-CAM和Integrated Gradient以及基于注意力的方法,如注意力流和注意力展开。
- 黑盒方法:这些方法系统地使用各种任务和数据探测模型,以估计其在一般情况中的行为,这被称为全局解释。虽然黑盒方法与模型无关,但也有一些方法如LIME和SHAP允许提供局部解释。
1 方法论
1.1 数据选择
本研究使用Saarbrücken语音数据库,该数据库包含来自1002名说话者的录音,其中454名男性,548名女性,以及851名对照组(423名男性,428名女性)。
- 说话者的年龄从6岁到94岁不等(病理组),以及9岁到84岁(对照组)。
- 每个录音会话包含/i/、/a/和/u/元音的中性、高、低、上升和下降音调的录音,以及简短短语“Guten Morgen, wie geht es Ihnen?”的录音。
- 音频以16位50kHz的采样率使用专业录音设备录制。
- 将参与者按性别和病理状态分组,病理状态分为三类:有机、无机和健康。
- 仅选择简短短语的录音,并将所有样本下采样到16kHz供模型使用。
1.2 模型训练
使用Audio Spectrogram Transformer (AST),一种无卷积、纯基于注意力机制的音频分类模型。它通过将音频转换为频谱图来处理音频数据,并使用视觉变换器(Vision Transformer,ViT)的架构来进行音频分类任务。
- 模型输入是t秒的音频波形,将其填充到模型的最大尺寸T秒,并转换为128维的log Mel滤波器组(fbank)特征序列,然后将其分割成16x16的块,并使用线性投影层将其展平,生成768维的嵌入序列。
- 每个嵌入都添加了可训练的位置嵌入(大小为768),以提供语谱图的空间结构,并在序列的开头添加了类别标记[CLS]嵌入(大小为768),并将其输入到Transformer编码器中。
- 编码器在类别标记[CLS]处的输出被提取为语音表示。
- 使用的模型在AudioSet上进行预训练,并在HuggingFace Transformers中实现和提供。
- 训练模型进行二元分类:病理(有机和无机)或健康受试者。
- 数据集按分层方式划分为训练集、开发集和测试集,比例为80%、10%和10%。
- 本研究比较了两种模型配置:
ast_freeze: AST模型设置为不可训练,并在模型顶部添加一个线性层,将嵌入投影到分类输出。
ast_finetuned: 与ast_freeze的构建相同,但AST模型设置为可训练,并对整个模型进行微调。
1.3 模型决策解释
本研究使用注意力回放方法可视化模型的决策过程。
- 该方法使用模型的注意力层生成相关图,以可视化语谱图区域的相关性分数。
- 通过将相关图与语谱图拼接成一个图像,并用色调表示相关性分数,用亮度表示频谱功率,从而可视化模型的注意力分布。
- 为了更好地理解语谱图区域,本研究使用Montreal Force Aligner生成与音频对应的语音音素标注,并将其添加到图像中。
- 根据两个模型的预测结果手动选择样本,分为四种情况:
O:ast_freeze和ast_finetuned都预测正确。
X:ast_freeze和ast_finetuned都预测错误。
A:ast_finetuned预测错误,ast_freeze预测正确。
B:ast_finetuned预测正确,ast_freeze预测错误。
2 结果
2.1 模型性能
下表显示了模型的性能指标,包括:

- 加权平均召回率 (UAR):不考虑类别样本大小的情况下,所有类别的平均召回率。
- ROC曲线下面积 (AUC):曲线衡量模型在不同分类阈值下的真正例率和假正例率。
与基础AST模型相比,ast_finetuned模型具有更好的性能,表明微调对模型预测的改善作用。
2.2 分析
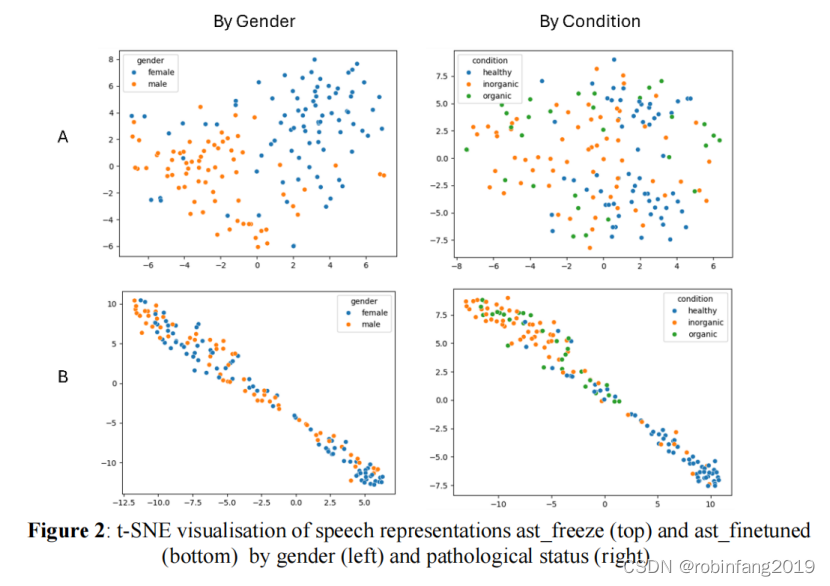
当基础AST模型未完全训练(A, ast_freeze)时,表示显示出性别之间的分离而不是病理状态(病理性与健康),换句话说,语音表示包含更多关于说话者性别而不是潜在声音病理状态的信息。另一方面,当基础AST模型完全训练(B, ast_finetuned)时,显示出相反的趋势。两个模型都无法清晰地分离有机和无机病理。
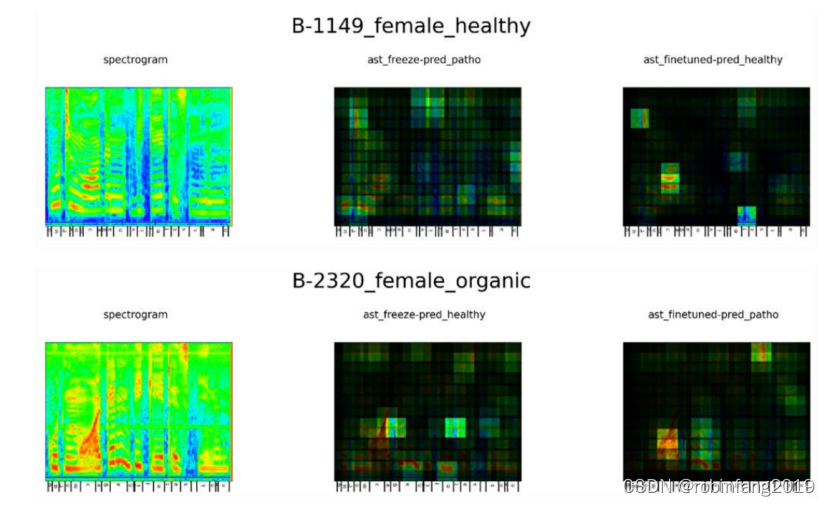
上图展示了两个女性语音样本的频谱图(左)和ast_freeze(中)与ast_finetuned(右)的相关性图(顶部:健康,底部:病理性):这两个样本的预测结果被标记为B,即ast_finetuned预测正确,而ast_freeze预测错误。
从可用的可视化中,我们可以看到最高相关性分数并不一定分配给最高强度区域,如基频和谐波。在两种模型中都出现的更常见模式是,它们给音素“/ɔ/”和音段“/e/ /s/ /i/ /n/”更高的分数。当模型微调后,我们发现更多的集中度,位置经常改变/移动,然而,没有得出明显一致的模式。
本研究训练和比较了两种Audio Spectrogram Transformer (AST) 配置,用于语音障碍检测,并使用注意力回放方法生成了模型的相关图。
通过分析相关图,发现模型无法完全识别有机和无机语音障碍之间的差异,并且模型对音素“/ɔ/”和片段“/e/ /s/ /i/ /n/”给予更高的分数。
当模型进行微调时,发现注意力范围往往会减少,这表明模型更加关注特定的音素区域。
3 模型配置
3.1 ast_freeze
- 模型类: ASTForAudioClassification
- 模型路径: MIT/ast-finetuned-audioset-10-10-0.4593
- 类别数量: 2
- 冻结: TRUE
- 评估策略: epoch
- 保存策略: epoch
- 学习率: 0.001
- 每个设备训练批次大小: 8
- 梯度累积步骤: 4
- 每个设备评估批次大小: 8
- 训练周期数量: 10
- 预热比率: 0.1
- 日志记录步骤: 50
- 评估步骤: 50
- 推送到Hub: FALSE
- 移除未使用的列: FALSE
- 早停耐心: 5
- 早停阈值: 0
3.2 ast_finetuned
- 模型类: ASTForAudioClassification
- 模型路径: MIT/ast-finetuned-audioset-10-10-0.4593
- 类别数量: 2
- 冻结: FALSE
- 评估策略: epoch
- 保存策略: epoch
- 学习率: 0.00025
- 每个设备训练批次大小: 8
- 梯度累积步骤: 4
- 每个设备评估批次大小: 8
- 训练周期数量: 40
- 预热比率: 0.1
- 日志记录步骤: 50
- 评估步骤: 50
- 推送到Hub: FALSE
- 移除未使用的列: FALSE
- 早停耐心: 8
- 早停阈值: 0